
About Carter Blum
I'm a current Computer Science Master's student at the University of Minnesota working with Prof. Paul Schrater. Last year, I spent time working in Baidu's Business Intelligence Lab under Prof. Hui Xiong in Beijing. and I'm hoping to pursue a PhD in the near future.
I am generally interested in reinforcement and meta-learning because I see these topics as deeply related to how we interact with the real world. I think that there is a lot of value to be added by adding structure to these models, so I'm particularly fascinated with model-based RL, causal reasoning, hierarchical RL and representation learning.
This site is still under construction, but, when complete, you'll find some of my larger projects in Academic Works, as well as some other ideas that I'm spitballing in the Blog section. I also review a paper every day, where I try to provide an intuitive and casual explanation of papers for people who have developed a background but are looking for more exposure to new ideas.

10 September 2020
The title says it all.
Ever wondered what tangible benefits your network is getting from transfer learning?
This paper analyzes a ResNet-50 that is initially trained on ImageNet but subsequently fine-tuned for various permutations of the DomainNet and CheXpert datasets.

02 September 2020
Recent work, including Hamiltonian Neural Networks, Recurrent Independent Mechanisms & Visual Interaction Networks have made strides by applying basic principles from physics to their model structure.
This work builds on the first of these Hamiltonian Networks to learn physical dynamics directly from pixels.
The authors further apply this to predict future pixels, resulting in a generative model based on invertible flow.

01 September 2020
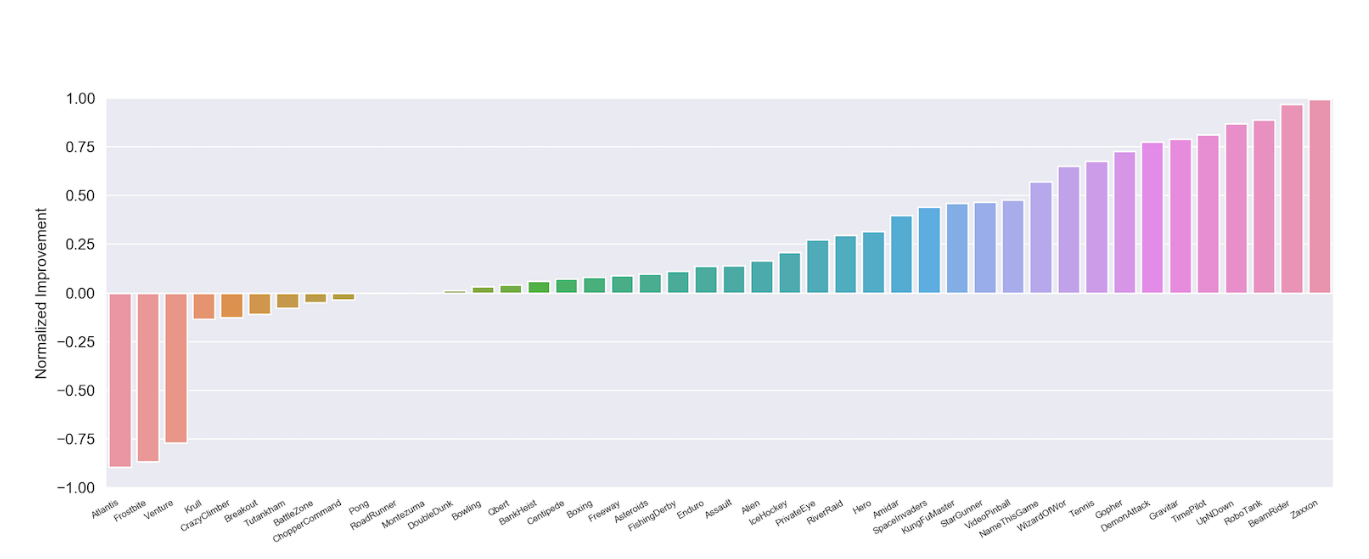
Curiosity, or intrinsic exploratory motivation, has been one of the hot-topics in RL recently.
This paper finds that an agent motivated by curiosity alone performs well on a large variety of tasks, which raises questions regarding the fundamental natures of the environments.

01 September 2020
How can we test how ethical an AI system is?
This paper proposes asking it questions.
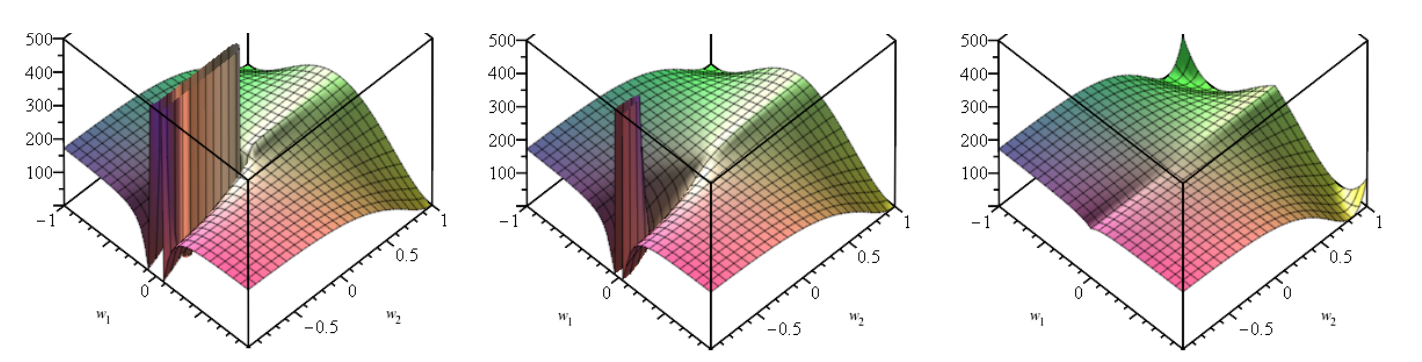
30 August 2020
Neural Networks can’t do addition. Or subtraction. Or multiplication.
Your first grader probably can. Let’s fix neural networks.
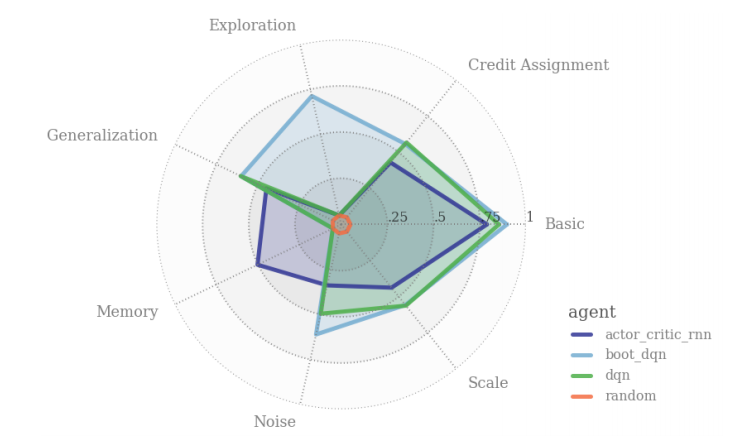
27 August 2020
Machine learning researchers have often lamented that it can be difficult to know exactly what your algorithm is struggling with.
What’s more, because of the incentives involved in the publishing process, authors often (perhaps inadvertently) present their algorithms in the best light, making it hard to objectively compare multiple works.
DeepMind has a new benchmark that might help ameliorate these problems.
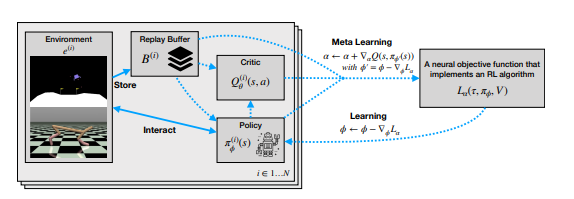
24 August 2020
One interesting aspect of reinforcement learning is that, while the value functions, Q-functions and policies are all learned automatically, the underlying algorithms, such as REINFORCE or Q-learning are not.
On a high level, this paper intends to learn a loss function that can be used to train a reinforcement learning agent by using meta learning.
Most crucially, it tries to do so on legitimately unrelated tasks, which is a stark departure from existing work.
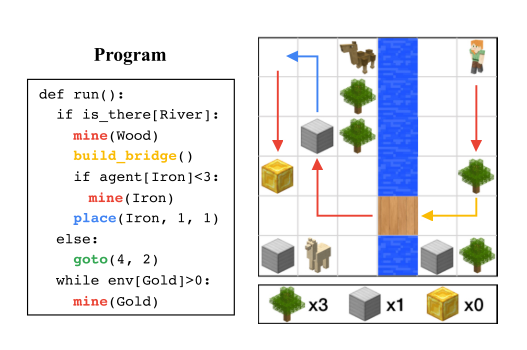
24 August 2020
Most of the great companies of the world today are built on code written by humans.
A lot of the time, problems that are easy for people are difficult for computers and vice versa (Moravec’s Paradox).
You might naturally ask - could we save machine learning some of the work by explicitly programming part of its behaviour?
This paper seeks to find out.
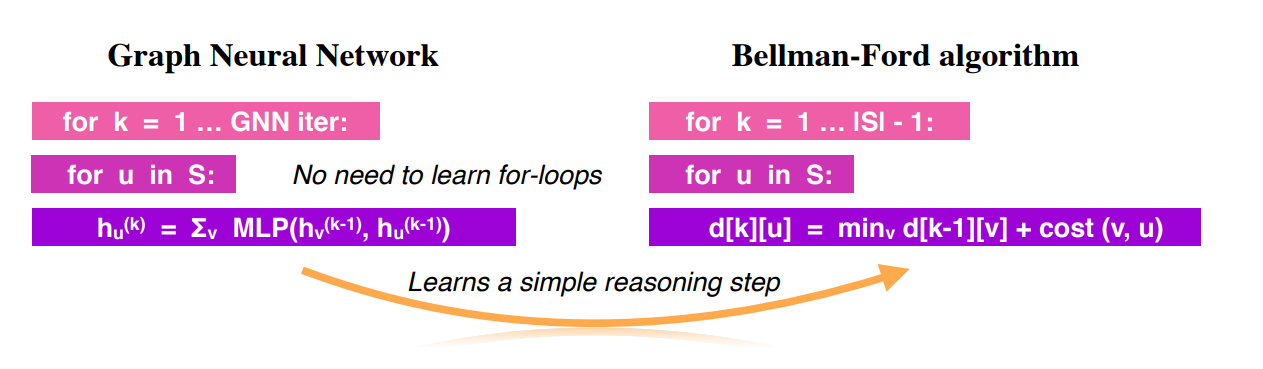
In an (algorithmically) ideal world, machine learning would be able to complete all of the tasks that traditional programs do.
However, it’s no secret that there are some functions that neural networks are able to learn better than others.
This paper seeks to quantify this intuition and provides a new concept called ‘algorithmic alignment’.
22 August 2020
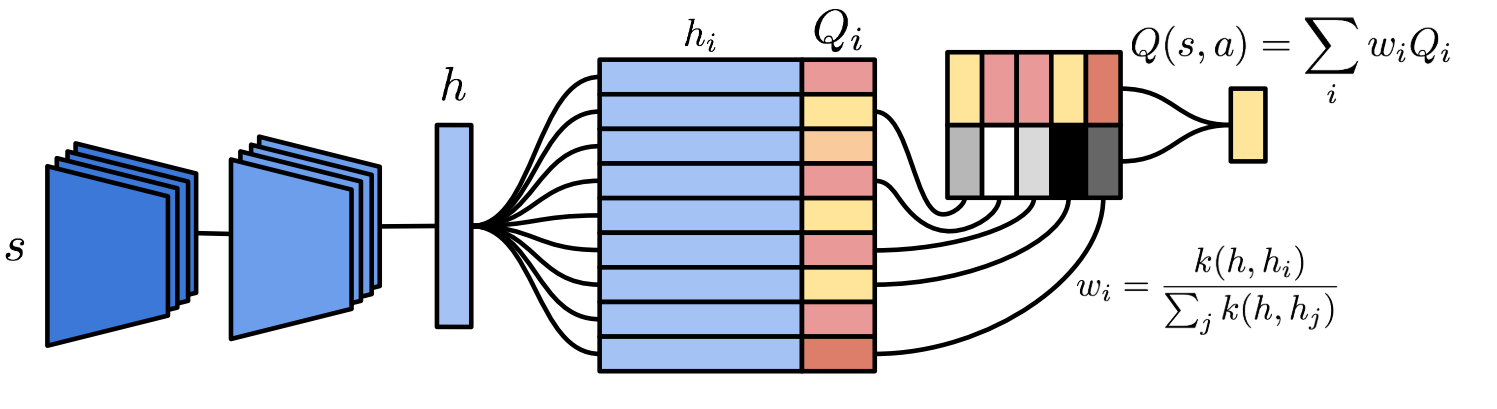
In this paper, we again talk about one of reinforcement learning’s favorite topics - why is RL so glacially slow?????
The authors provide a number of hypotheses as to why this may be the case and then propose a model based on non-parametric memory that speeds up learning significantly on a number of tasks.
To summarize it in one sentence: what if we estimated the Q-value of new observations to be a weighted sum of the Q-value of similar observations?
21 August 2020
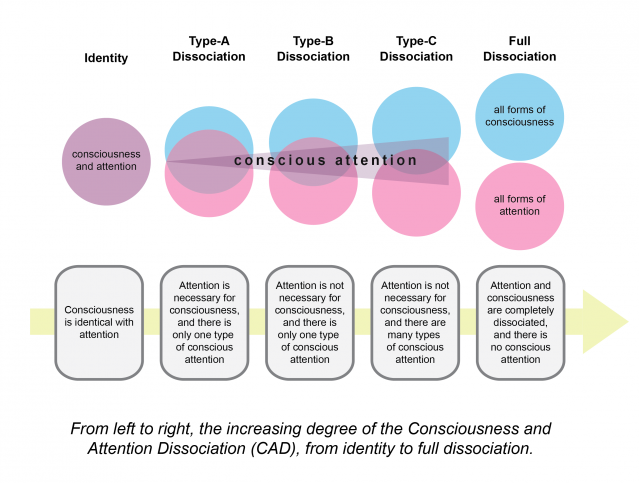
Recent psychology suggests that what we think of as conscious thought may simply be selective attention paid to certain (mental) objects, with many other things being ignored by our conscious mind.
Yoshua Bengio’s “consciousness prior” attempts to turn this psychological principle in to a useful machine learning principle, by using a subset of the available information to model dynamics using a sparse factor graph.
21 August 2020
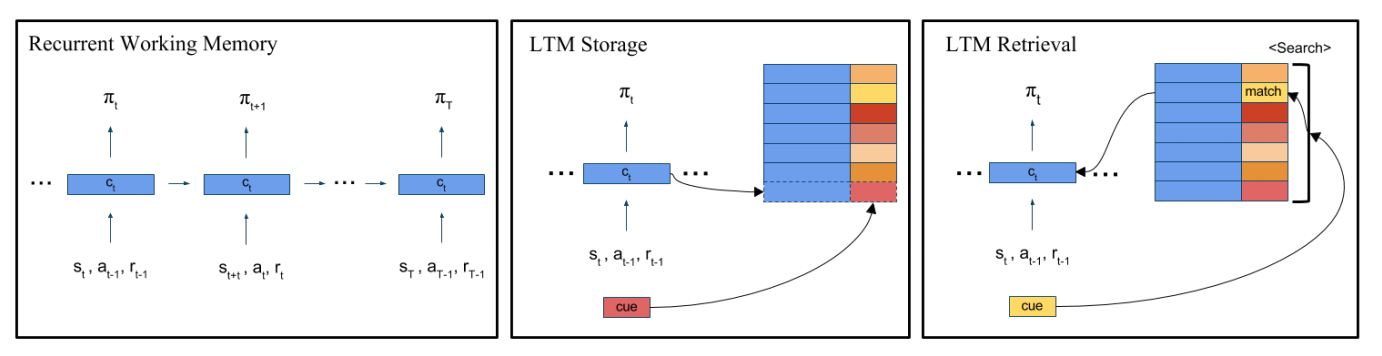
As the deep learning community grapples with the ever expanding costs of training ever-larger models, a number of possible strategies for circumventing these problems have emerged. Among them, meta-learning (or ‘learning to learn’, a term we apparently stole from psychology) hopes to find ways to speed up the learning process by jointly learning about multiple processes. In reinforcement learning (incidentally, another term stolen from psych), episodic control leverages short-term memories to, you guessed it, learn more efficiently about the environment. This paper frames the episodic control as a form of meta-learning (literally the title) and provides a new memory structure...
19 August 2020
Some of the greatest leaps forward in neural networks have come from removing connections instead of just adding them.
Convolutional Neural Networks reduce connections to maintain translational invariance, LSTMs limit interference with their long-term memory and GShard uses sharding to save computation.
A lot of scientific models are predicated on similar principles to model the world : \(f=ma\) doesn’t ask you to know the pressure surrounding the object it’s modeling.
Recurrent Independent Mechanisms take a step to extend this principle by creating weakly-interactive recurrent models for objects.
18 August 2020
If you were looking for a paper to stoke fears that superhuman intelligence is right around the corner, this is not your paper (I recommend googling GPT-3 though).
If you were looking for a paper to convince you that the field of machine learning is a sham, this is not your paper (I recommend this paper).
If you were looking for a paper to get as close to science as ML ever gets, this is your paper.
17 August 2020
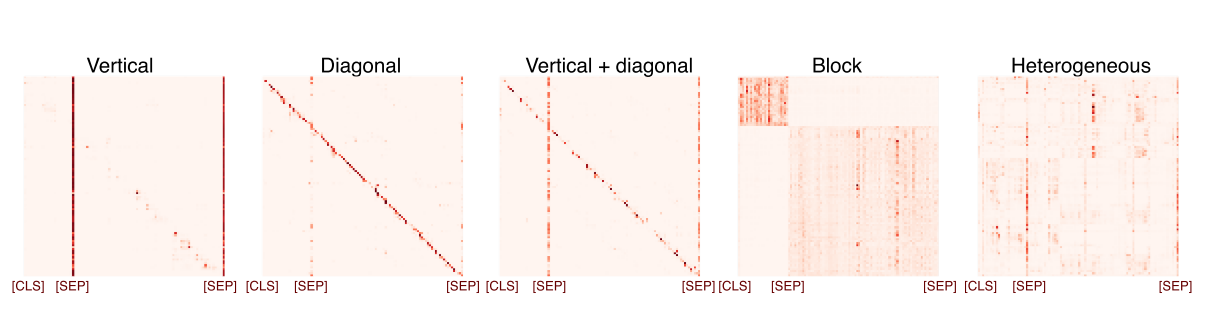
One of the hardest topics in reinforcement learning is exploration, choosing which things are worth trying.
Some methods try to avoid visiting states twice in the same episode, while others try to diversify exploration over the life of the training process.
DeepMind’s “Never Give Up” algorithm tries to do both.
Header Image Credit:One of the cores of the old paradigm of AI (symbolic manipulation) was the concept of the knowledge base, representing all of the agent’s knowledge about the world.
One form of knowledge base was the knowledge graph, which can represent knowledge through predicates such as ‘isCitizenOf(Carter, Minnesota)’.
Unfortunately, actually using these graphs to derive implicit relations can be really computationally expensive.
This paper attempts to use reinforcement learning to efficiently traverse the knowledge base to answer queries.
16 August 2020
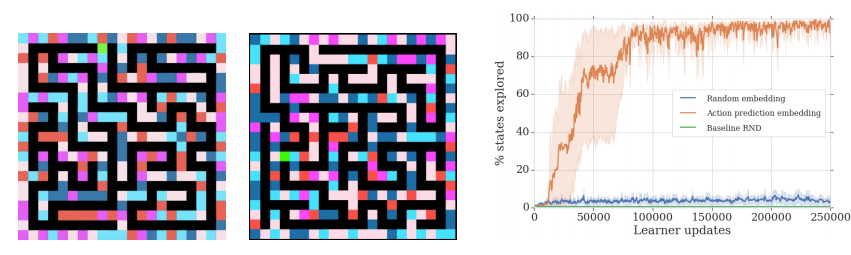
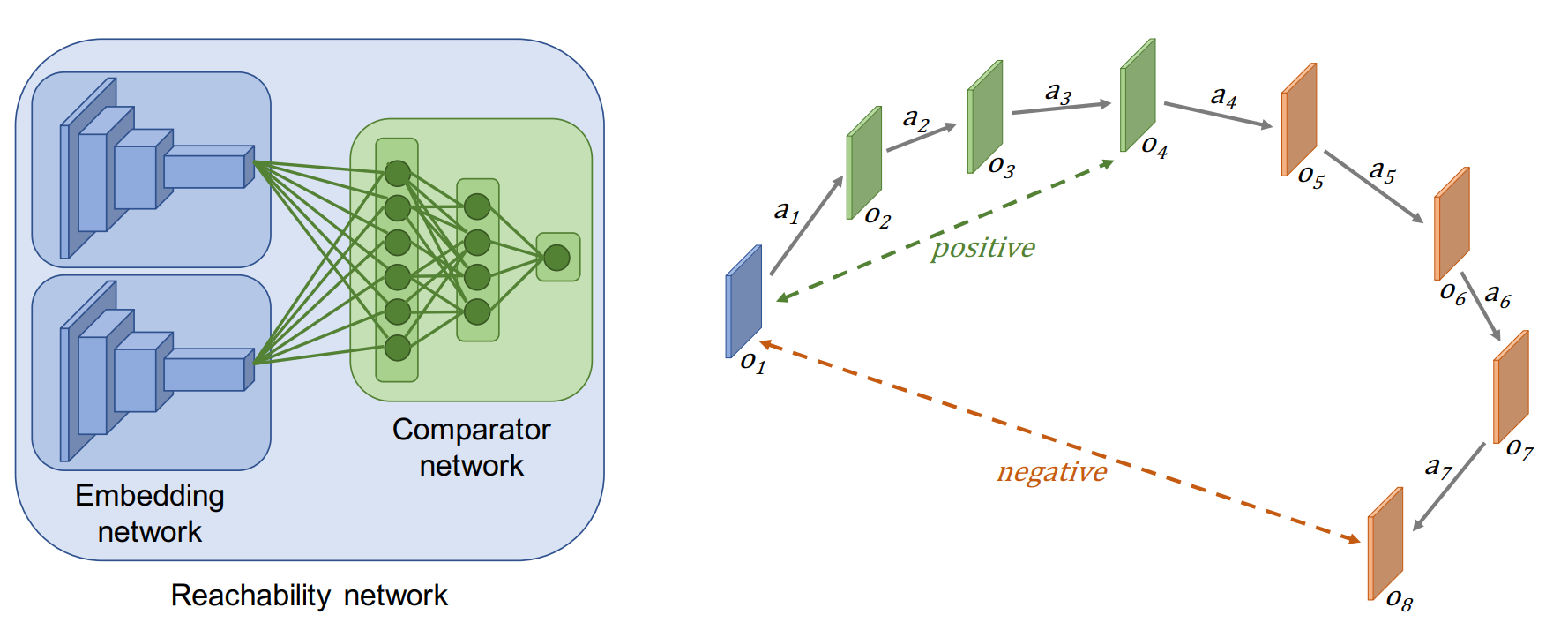
One of the largest hindrances in reinforcement learning has been solving problems with sparse rewards: how do you know if you’re doing the right thing if you don’t get any feedback?
One solution is to simply try a lot of new things - eventually you’ll find one that works.
This naturally raises the question - what qualifies as new? This paper takes a stab at it by examining path length between observations.
15 August 2020
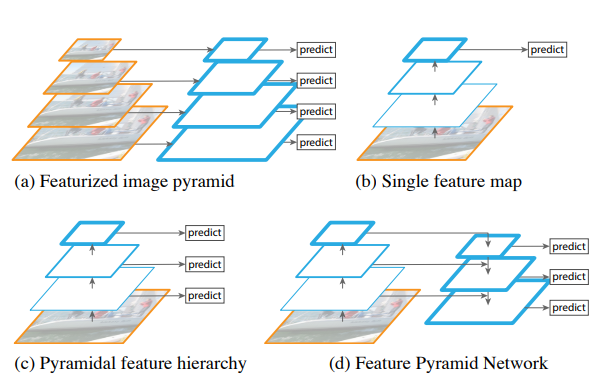
By this point, it’s pretty well-known that the lower levels in a CNN contain lower-level features, while the upper layers tend to have more abstract and rich features but at lower resolution.
This paper asks the question - why can’t we have the best of both worlds?

Visual Question Answering is the task of answering questions posed in natural language about an image.
The task involves not only processing the elements of an image, the syntax of a system, but also putting them together in potentially complex ways to guess at an answer.
As a result, learning modules that combine all of these aspects in to one model can be difficult.
This paper proposes lightening the load on the model a little bit by using symbolic programming.
13 August 2020
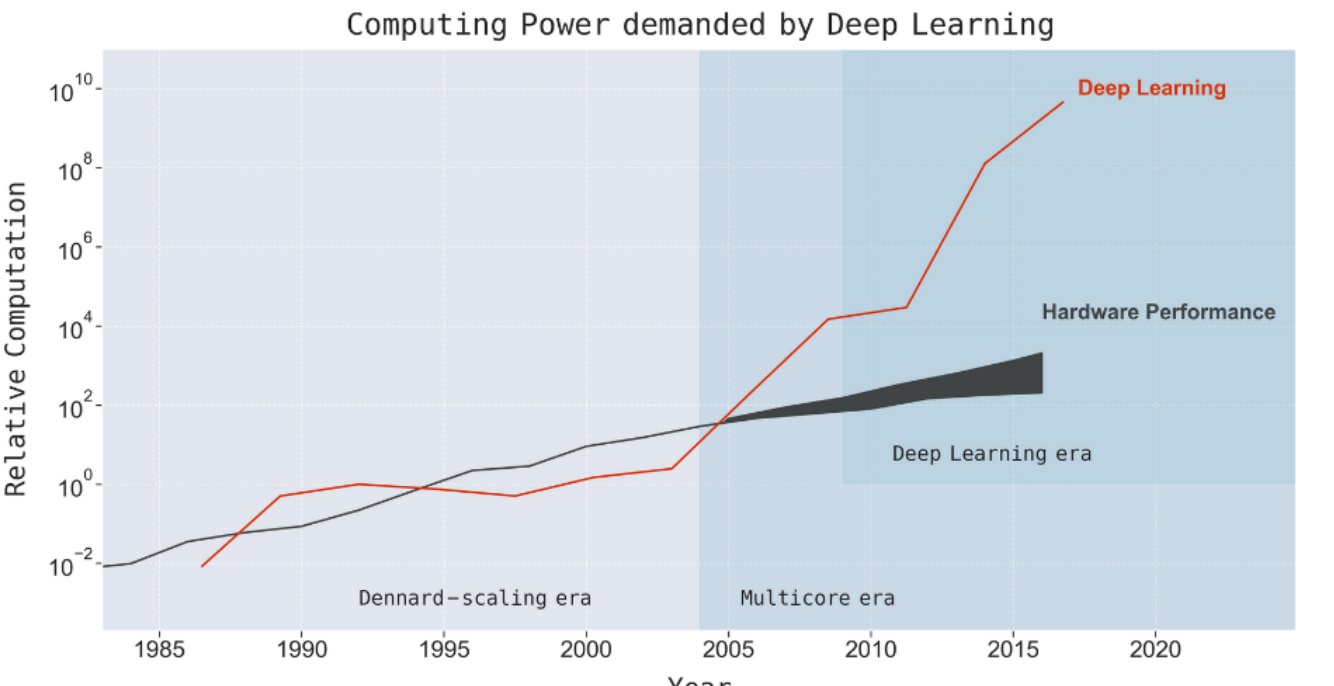
Since AlexNet made world news in 2012, advances in Artificial Intelligence have created headline after headline.
These advancements have largely been driven by neural networks, which have shown a voracious appetite for data and computing power.
While deep learning’s demand for power has grown exponentially, Moore’s law is dead and computing speed is not increasing at the same pace.
how long can this go on?
12 August 2020
Transformers are all the rage nowadays - they’ve made huge strides in many tasks, including enabling the massively successful language model, GPT-3.
Hopfield networks, invented in 1974 and popularized in the 80s, are largely considered to be old news.
The previous post, found here provided a primer on Hopfield networks.
In this post, we’ll explore the connections between transformer models and Hopfield networks.
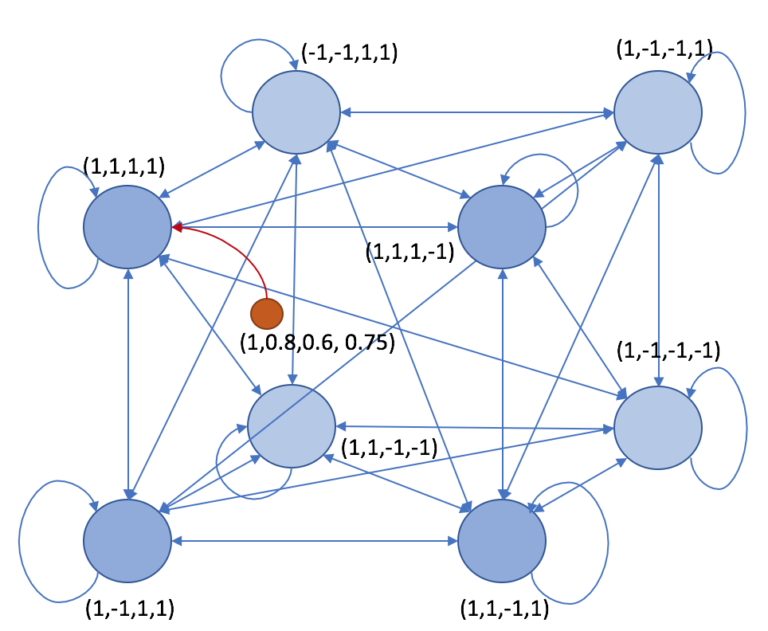
10 August 2020
Transformers are all the rage nowadays - they’ve made huge strides in many tasks, including enabling the massively successful language model, GPT-3.
Hopfield networks, invented in 1974 and popularized in the 80s, are largely considered to be old news.
However, they’re not as different as you might think.
This post lays the groundwork of understanding for how Hopfield networks function.
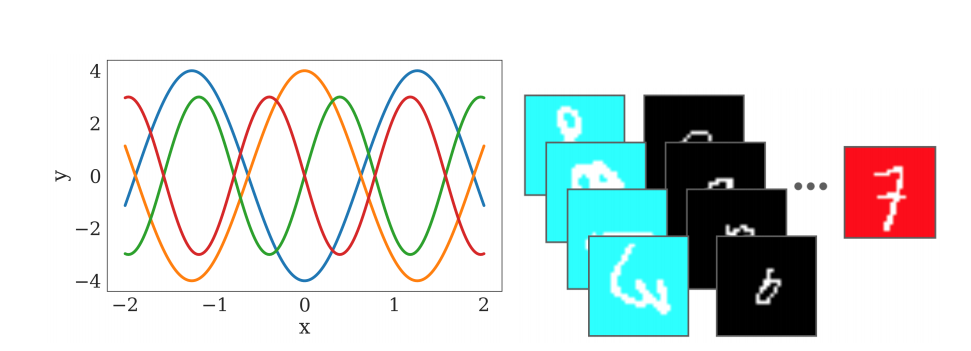
10 August 2020
Modern deep learning methods have gotten extremely good at learning narrow tasks from large troves of data - but each model is often a one-trick pony.
Models often need huge amounts of data, struggle to extrapolate from one task to another, and can experience catastrophic forgetting (melodramatic much?) when they have to learn new tasks.
Is it possible that a single approach could help solve all three problems at once?
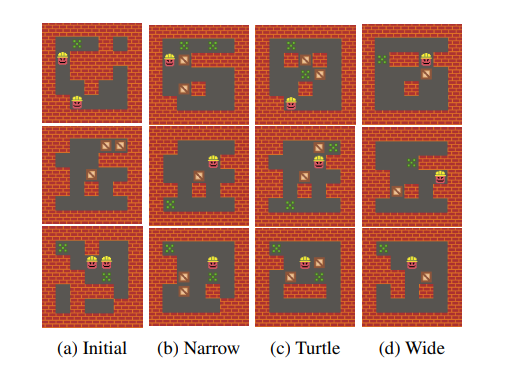
Level-design can make or break a game.
Many games either design levels manually or use complicated algorithms to generate new areas for players to explore.
Both of these approaches can be expensive, costing a lot of human labor to implement.
Can we automate the process using reinforcement learning?