PCGRL: Procedural Content Generation via Reinforcement Learning
08 August 2020
Level-design can make or break a game. Many games either design levels manually or use complicated algorithms to generate new areas for players to explore. Both of these approaches can be expensive, costing a lot of human labor to implement. Can we automate the process using reinforcement learning?
Authors
- Ahmed Khalifa (PhD Candidate, NYU - Game Innovation Lab)
- Philip Bontrager (PhD Candidate, NYU - Game Innovation Lab)
- Sam Earle (https://github.com/smearle)
- Julian Togelius (Assoc. Prof., NYU - Game Innovation Lab, Tandon Future Labs)
ArXiV: https://arxiv.org/pdf/2001.09212.pdf
Background
As I’m sure most people our generation don’t need to be told, many games are organized in to levels. Levels serve as nice, discrete tasks that the player must complete before progressing on to the next one. These levels should ideally be just difficult enough to solve that the player feels like they made progress, but not so hard that the player gets frustrated. Above all else, these levels should be solvable - there’s little that’s more frustrating than spending hours solving a problem solving a puzzle that can’t be solved.
These levels are usually created either by algorithms that procedurally place objects in a level or by people who have to hand-place every single object in the game (or some mixture of those two).
Skyrim gets even more impressive when you consider that someone had to figure out where to put every single tree
Given that we have a fairly laborious process in level design, the authors ask an interesting (and fairly natural) question: can we automate it?
Core Idea
The authors phrase the question as a reinforcement learning (RL) problem. Starting with an arbitrary level, the reinforcement learning agent is tasked with changing the environment to create a better environment. The agent is rewarded according to how solvable the level it generates is - it’s that simple!
Details
To pose the problem as a RL problem, we have to define the basic parts of an MDP:
- \(S\) : the state space, here it’s just a representation of the current level design
- \(R\) : the reward function, used as a signal to tell the agent how good it’s current design is. This will be further explored in the experiments section.
- \(T\) : the transition function is deterministic in this place - just implement whatever changes the agent makes to the level
- \(A\) : the action space, how the agent actually changes the level. The authors explore several options in their experiments.
Once we define these 4 parts of the MDP (as well as \(\gamma\), the discount factor), any reinforcement learning algorithm can be applied, as long as it handles discrete actions in an episodic environment. That’s exactly what the authors do - they use a pretty standard algorithm, Proximal Policy Optimization (PPO) for all of their experiments.
Experiments
The authors test three different games to design levels for. To simplify things, all of the environments are discrete toy environments.
- Binary : A maze where each tile either has a wall or is empty. The agent tries to increase the longest shortest distance between any two points and is rewarded for achieving this goal.
- Zelda : A game set up similarly to the maze, where the player has to grab a key and go to a door while avoiding enemies. A level is considered ‘valid’ if it has exactly 1 door, 1 player and 1 key and the level can be completed in some finite number of steps.
- Sokoban : An old Japanese game that you can apparently download on your phone. There are crates on the ground and targets that the crates have to be pushed on to. They considered a maze valid if it’s solveable in X steps (they chose X to be 18).
The agent is rewarded for making changes that make the levels ‘more’ valid. For each of the three environments, the authors consider 3 different action spaces.
- Narrow : The agent considers at each cell of the grid and chooses whether or not to change the contents of the cell.
- Turtle : The agent considers at one cell at a time, and then chooses which adjacent cell to consider next.
- Wide : The agent considers all of the cells at once, and chooses a cell to change and how to change it.
You can see some of the level designs below - they look pretty reasonable.

Sample results of fully trained agents making binary mazes
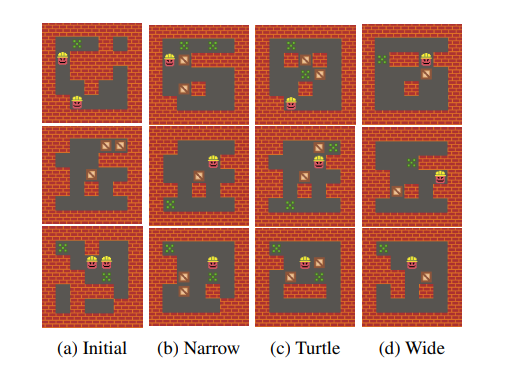
Sample results of fully trained agents acting on Sokoban
Finally, to try to force the agent to discover more diverse solutions, they limit the ‘edit distance’ from the initial level design.
This prevents the algorithm from always generating the same map, as the initial level design is randomized.
Given these constraints, here’s how often the agents were able to generate valid levels for each of the games.
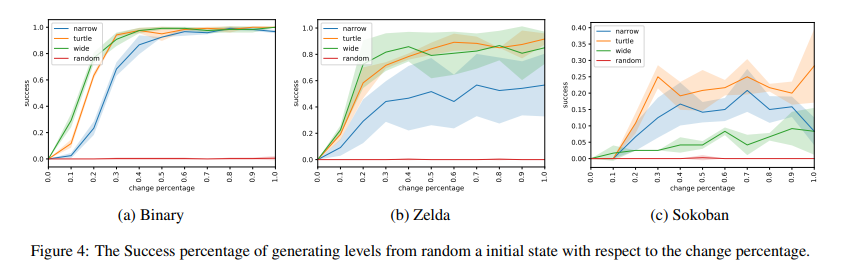
Each line represents a different action space used to train the model
Unsurprisingly, your chances of randomly generating a level just aren’t that great.
While pretty much all of the action spaces enable the agent to create valid Zelda and Binary environments nearly all of the time.
Sokoban is a lot harder than the others - the best agent doesn’t really get over a 30% success rate.
Interestingly, wide - which is technically the most flexible model doesn’t provide the best results.
My guess would be that this dynamic would change if you just through enough compute power at it.
Future Directions
I think that this is a really cool direction with some interesting applications. The most obvious application of this might actually be curriculum training, trying to create environments that agents can learn to solve easily. That might be really expensive because you’re ‘doing RL in the inner loop’ (in order to evaluate your RL agent’s level design, you need to train another RL agent), but it seems reasonable that designing/recognizing hard and easy problems is easier than solving them, so this could be a promising direction.
If you wanted to actually apply this to levels being played by humans, I think you would need a lot of tweaking. One really interesting question is if you could establish some correspondence between the learning behaviour of RL agents attempting to solve a level and human enjoyment of that same level. If you could do this, then you could train the algorithm to generate levels that induce some behaviour in an RL agent, and, in doing so, create levels that are actually fun, while minimizing the need for human trials.
My best guess would be that a ‘fun’ level is one where the player continually progresses for as long as possible. In an ML agent, that would look like a learning curve that never really plateaus. Of course, that has some tacit assumptions - the RL agent doesn’t necessarily learn the same way a person does, but it might be a good proxy (unless you’re using a DQN, which is widely known to plateau right at the beginning of training).
General Thoughts
I think that the most major contribution of this paper is the novel problem. Applying reinforcement learning to game design isn’t something I’ve seen before, and I think that the more general problem of getting AI’s to build interesting problems is … well, interesting!
That being said, I think that the results here leave a lot to be desired. The games that they are building are still very simple, and I’m not super convinced that the agent is learning anything deep. If your only goal is ‘valid’ level design, it’s extremely simple to code up traditional programs to solve all of these problems. I’m not completely sure if there’s a path for this to generalize to more complex domains or more nuanced definitions of ‘good level design’, but it definitely piqued my curiousity.
P.S. I was made aware of this paper on Yannic Kilcher’s YouTube channel - it’s an excellent resource, I completely recommend checking it out!!!