Feature Pyramid Networks for Object Detection
15 August 2020
By this point, it’s pretty well-known that the lower levels in a CNN contain lower-level features, while the upper layers tend to have more abstract and rich features but at lower resolution. This paper asks the question - why can’t we have the best of both worlds?
Authors
- Tsung-Yi Lin (Sen. Res. Sci. - Google)
- Piotr Dollar (Res. Mgr. - FAIR)
- Ross Girshick (Res. Sci. - FAIR)
- Kaiming He (Res. Sci. - FAIR)
- Bharath Hariharan (Asst. Prof., Cornell)
- Serge Belongie (Prof., Cornell)
ArXiV: https://arxiv.org/pdf/1612.03144.pdf
Background
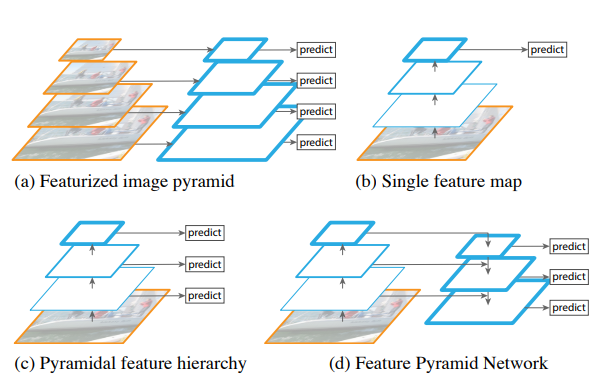
Back in the dark-ages of hand-engineered features, one common approach was to input images to algorithms at a variety of scales when doing feature detection. Calculating these features at different scales resulted in a feature pyramid, which could be used for a variety of tasks. This was a computationally expensive way to achieve scale-invariance, which has long been a desirable property in computer vision models.
In the modern era, CNNs can be viewed as doing something similar, with features at the higher levels of the CNN having a greater visual input field. However, the features at each level are different, and the higher levels, while having rich features, contain very little information about localization. Ideally, we would like to be able to better pin-point which pixels are more responsible for high-level features.
Core Idea
Most neural neural networks only contain a forward pass through the network.
This paper proposes adding a backward pass to CNNs, propagating information from higher levels back down to earlier levels, as shown below.

During the backward pass, the information from the higher levels is upsampled and combined with the information at the lower level.
This information can then be used immediately for predictions at that resolution or can be passed to the prior level.
Details
After upsampling, the information from the higher levels is combined with the lower level using what the authors refer to as a ‘lateral connection’.
The lower level’s data is transformed by a 1x1 convolution before adding it to the features of the higher level.

It's not immediately clear to me why this precise connection pattern was used, I could just as easily see something like concatenation being used (although this does require less memory). Nonetheless, the author's results indicate it's an important step.
These features themselves may go through convolution before being passed to the next layer.
One important thing to note is that the authors suggest skipping any backward passes where the size doesn’t change.
This makes intuitive sense : the only reason that we’re doing the backward pass in the first place it to try to get more spatial resolution.
If we work with the assumption that the higher-level features are richer than lower level ones, then the lower-level layer provides no additional information unless it has greater spatial granularity than the higher level.
If it doesn’t then we can skip it and input our higher layer’s information directly in to the whatever the next layer that we find increases in size is.
Experiments
The authors do one thing that I quite admire : in all of their models, they attempt to change the model minimally from existing state of the art.
This shows that their improvements are robust and aren’t just the result of better hyperparameter hacking or training time.
Well, it could still technically be training time, but I digress.
They do a lot of extensive tests, all with very convincing results, so I’ll just drop them here:

Future Directions
The first thing I wonder is whether or not this could be extended to a more general principle. For instance, if the higher layers provide information that is truly useful when looking at lower-levels, who’s to say that that information couldn’t also be useful when doing a second pass through the network? It’s not hard to imagine a scenario where one lower layer initially labels something as an eye, but a higher level identifies that there’s probably a moth there. This information could be passed back through the network to help it discover that what it thought was an eye was actually a pattern on the moth’s back. This could in turn increase its confidence that it really was a moth, which informs its predictions in other areas of the network. A concept of self-coherence by getting different layers of a network to agree with each other could be a really useful tool for getting the network to develop more robust representations.
General Thoughts
The idea here is quite simple, but very well-executed and well-tested. This is a paper I’ve seen cited numerous times, so I finally took the leap and read it. I can absolutely see why it has had such an impact. Even if it doesn’t provide very much theoretical understanding, it’s a well-done engineering paper.