DeepPath: A Reinforcement Learning Method for Knowledge Graph Reasoning
16 August 2020
Header Image Credit:One of the cores of the old paradigm of AI (symbolic manipulation) was the concept of the knowledge base, representing all of the agent’s knowledge about the world. One form of knowledge base was the knowledge graph, which can represent knowledge through predicates such as ‘isCitizenOf(Carter, Minnesota)’. Unfortunately, actually using these graphs to derive implicit relations can be really computationally expensive. This paper attempts to use reinforcement learning to efficiently traverse the knowledge base to answer queries.
## Authors
- Wenhan Xiong (PhD Cand., Will Wang Lab - UCSB)
- Piotr Dollar (Soft. Eng. - Google)
- Will Wang (Asst. Prof. - UCSB)
Link: https://sites.cs.ucsb.edu/~william/papers/DeepPath.pdf
Background
Knowledge graphs are a common form of knowledge base, consisting of discrete objects and predicates that act upon them. For instance, your graph might have predicates such as
\(isCitizenOf(Carter, Minnesota)\), \(isStateOf(Minnesota, USA)\)
indicating that Carter is a citizen of Minnesota and Minnesota is a state of the USA. From this, if you want to know what country Carter is a citizen of, you could apply a rule like
\[isCitizenOf(x, s) \ and \ isStateOf(s, c) \ then \ isCitizenOf(x, c)\]We can generalize this problem to the problem of finding a path between any two given nodes.
You could use standard graph algorithms like breadth-first search or depth-first search to try to find these paths, but this is computationally extremely expensive.
These problems of computational complexity, in conjunction with difficulties designing/collecting a sufficiently large knowledge base, have kinda’ caused the strategy to lose traction in recent years.
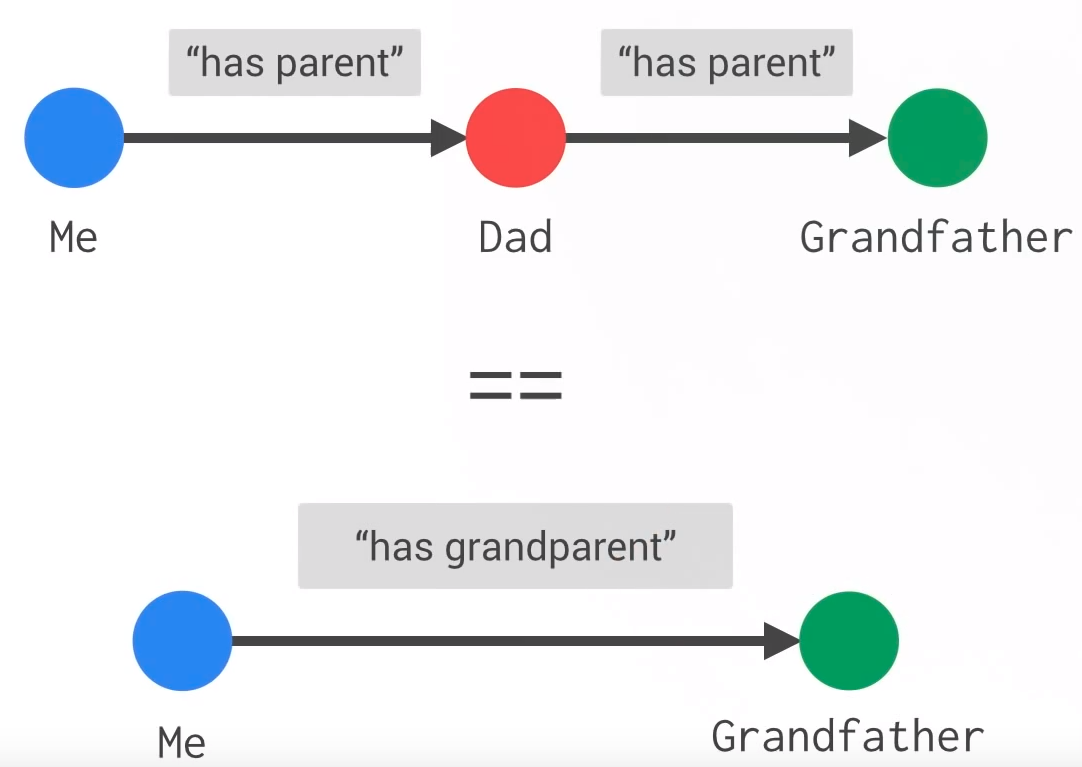
I recommend [this article](https://medium.com/@Dezhic/understanding-knowledge-graphs-5cb05593eb84) for a good review of knowledge graphs
Core Idea
We can frame the knowledge space as an environment and relationships as actions. For instance, given a state ‘Carter’, we can choose to apply action ‘isCitizenOf’ to get ‘Minnesota’. With this framework in mind, we can phrase the problem of finding a path between two nodes as a reinforcement learning problem - we start at the first node and get a reward when we find the second node. Hopefully, this algorithm chooses relations to search through that generate results faster than existing algorithms after it is trained.
Details
This paper has a lot of separate ideas going on, so I’ll try to cover some of the key points:
- The reinforcement learning algorithm is initially trained with imitation learning on some paths.
- The algorithm considers all of the possible relations as outputs at each time step.
- Embeddings are calculated for the nodes in the graph
- The state is encoded as the embedding for the current node concatenated with the difference between the target embedding and the actual embedding.
- The agent receives 3 different types of rewards (all summed together)
- It receives positive reward for paths ending in a successful find and negative reward for paths that don’t find their target.
- It receives an additional reward discouraging longer paths \(r_2 = \frac{1}{length(p)}\) for a path \(p\) generated by the RL agent
- It receives yet another reward encouraging diversity
- The algorithm also tries to do a bidirectional search starting from both the target and the start
- If you’re interested in further details, feel free to check out the full paper!
Experiments
The authors use two databases for their testing : FB15K-237 and NELL-995.
I’m not personally familiar with either database, so I can’t comment on any characteristics of their choices of testbeds.
Their primary comparison target is another algorithm called PLA (which I’m also not familiar with), and in general their algorithm needs to create fewer paths than their competitor before getting a successful one.
This is shown below :
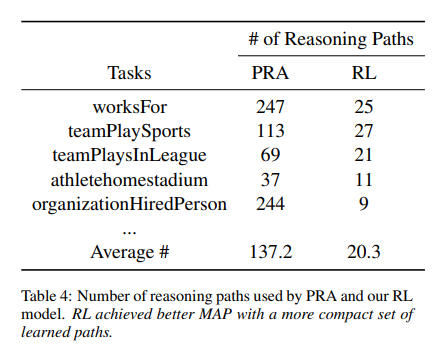
They still need to generate a lot of paths though
Additionally, these paths tend to be pretty short:
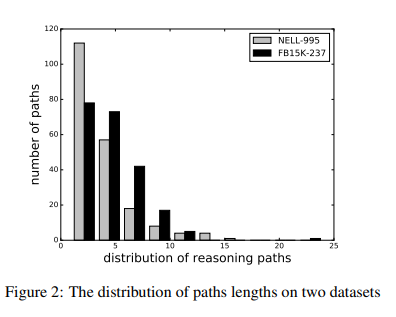
You can look at these short paths in two ways. One is that the queries that they’re being tested on are really simple - usually only requiring two relations to get a solution.
The second way is to look at it as proof that the algorithm tends to find pretty concise logical flows.
I think that there’s definitely merit to looking at both.
Future Directions
I actually really like the idea of using RL to speed up graph search. Even beyond this situation, I think it has the potential to provide large speed-ups over existing algorithms without needing to be trained in a domain specific manner. It’s also very possible that a model like this could be enhanced by a simple language model : making it more likely to choose relations that co-occur with the target. For instance, if you’re looking for the node ‘USA’, regardless of where you’re starting from ‘isIn(x, y)’ is more likely to give you a ‘USA” back than ‘colorOf(x, y)’.
General Thoughts
That being said, I don’t think that I see as many of the details of this paper as core players moving forward. This work felt like it used a lot of engineering tricks and other changes to get a good result, which makes me less certain of the validity of the central idea. I like the base idea, but a more complex algorithm is not necessarily a better algorithm.