
(ETHICS) : Aligning AI with Shared Human Values
01 September 2020
How can we test how ethical an AI system is? This paper proposes asking it questions.
Authors
- Dan Hendrycks (PhD Cand. - Berkeley (advised by Song & Steinhardt))
- Collin Burns (Undergrad - Columbia w/ Steinhardt)
- Steven Basart (PhD Cand. - UChicago)
- Andrew Critch (Res. Sci. - Center for Human Compatible AI, Berkeley)
- Jerry Li (Sen. Res. Sci. - ML & Optimization Group, Microsoft Redmond)
- Dawn Song (Prof. - BAIR, BDD, Center for Human Compatible AI, Berkeley)
- Jacob Steinhardt (Asst. Prof. - BAIR, Berkeley)
Background
AI Ethics is a real problem, on many fronts. There have been a ton of examples of AIs gone wrong, where models learned to emulate some of the worst behaviours of humans (see Microsoft’s Tay for an example). It’s such a tricky subject that Google has even started offering AI Ethics as a Service (they don’t have it figured out either).
Perhaps the central problem in AI ethics is that of AI alignment. If humans create a super-human AI, we want to be sure it will treat us well, otherwise that could go disastrously for us. The mere fact that it’s super-intelligent does not imply that it’s super-moral (see the orthogonality thesis). We’re still extremely far from solving this problem and many (myself certainly included) feel that we’re not devoting enough effort to solving this problem.
However, humans haven’t even come to an agreement between ourselves regarding what is ethical, let alone codifying it in to a set of rules that can be encoded in to an AI agent. If you doubt that, just look at how vehemently people disagree over political topics - who is to say who is right and who is wrong? Such tricky ethical questions (combined with the fact that deep learning is still largely a black box) have stymied many efforts in this area.
Core Idea
This paper attempts to find a common denominator of human ethics and test an AI system on that. The result of this is an ETHICS dataset, which contains a number of natural language tasks that can be used to evaluate an agent.
The authors select 5 common ethical frameworks (justice, deontology, virtue ethics, utilitarianism and ‘commonsense morals’) and devises NLP questions to test each of them. To ensure that the questions are fairly morally universal, the authors use Amazon’s Mechanical Turk to elicit the judgments of everyday people. Only questions that were almost universally agreed upon were added to the dataset.
Details
In order to understand what the authors are testing, it’s important to understand the moral frameworks that they’re testing:
- Justice : These questions emphasize fairness and impartiality
- Deontology : Rule-based theories of morality that focus what one must do to be a good person
- Virtues : Morality that centers around virtues like honesty, kindness, work ethic, etc.
- Utilitarianism : Views that the morality of an action is defined by its (intended) effects
- Commonsense : Kicking people is generally mean.
To test each of these, they come up with a number of different NLP tasks, which are as follows:
Justice
These tasks test whether the AI is able to identify scenarios where it should treat people fairly. The authors divide this in to two parts: ‘impartiality’ (treating people the same without respect to their superficial qualities) and ‘desert’ (making sure that people get what they deserve or are entitled to). One entertaining part of this paper is that they give computer science allegories for different ethical principles. In this example, the authors equate figuring out who deserves what to a credit assignment problem.
Some sample problems are shown below:

It's not hard to think of scenarios where these questions might have different answers - for instance, what if you stole a candy bar while also trespassing?
Virtues
The authors explain virtue ethics as emphasizing whether people exhibit good and bad character traits (for this, they site Aristotle from 340 BC, which is great).
The authors ask the model to predict which virtues or vices might be present in a given example.
Their computer science explanation is that this is similar to learning to imitate exemplary examples.
I’m not convinced that this is entirely fair - while virtues are often communicated via stories and parables, I don’t think that’s necessarily core to virtues.
An alternate way to look at virtues is as identifying essential common traits that good examples share, and attempting to maximize those traits.
Some such positive traits might be stuff like honesty or loyalty, while some vices might be addiction or a quick temper.
Example questions below:

Some adjectives don't seem like virtues or vices. For instance, how would you classify 'awkward'?
Deontology
If you’ve ever met someone who religiously adheres to rules, then you probably have a decent idea of how deontology works.
The authors create two tasks to test this area.
In the first task, the AI has to identify in what situations it is still ‘obligated’ to comply with a request.
In the second task, the AI has to recognize what rules & obligations can be expected of people in different roles.

In some way, these feel almost like tests on social skills - what's a valid excuse for a request?
Utilitarianism
You can think of utilitarianism as being defined by some utility function, where people should make actions that lead to states with a higher utility.
For many people, the utility function would probably be to maximize total human happiness (although, in practice, nobody is truly that altruistic).
To that extent, the tests for utilitarianism consist of identifying which of two situations is preferable (i.e. has a higher utility).
As always, example shown below:

Common sense
In these tasks, the authors provide a number of short stories. Some are one or two sentences, and are generated using Mechanical Turk. Longer ones, (1-6 paragraphs in length) are curated from Reddit using filters (I haven’t checked, but I strongly suspect that reddit.com/r/AITA was a major source here). For the mechanical turk samples, the authors are instructed to write scenarios where someone does something that is clearly wrong or is clearly not wrong. The reddit posts are taken from subreddits where users describe a scenario and readers vote whether or not the author acted wrongly.
The agent has to identify whether or not the subject in the stories acted correctly. As noted above, all samples are generated using workers from Amazon’s Mechanical Turk, unless noted otherwise. The authors note that the total dataset has 130K samples in it, which is quite impressive. For each task, problems are separated in to easy and hard sets.
Experiments
The authors test a number of NLP models on each of these tasks.
Most of the tests work like you would expect with fairly standard loss functions given the descriptions above.
The training process is generally to take the pre-trained model and fine-tune it for each task.
The scores for each of the models that were tested are listed below:
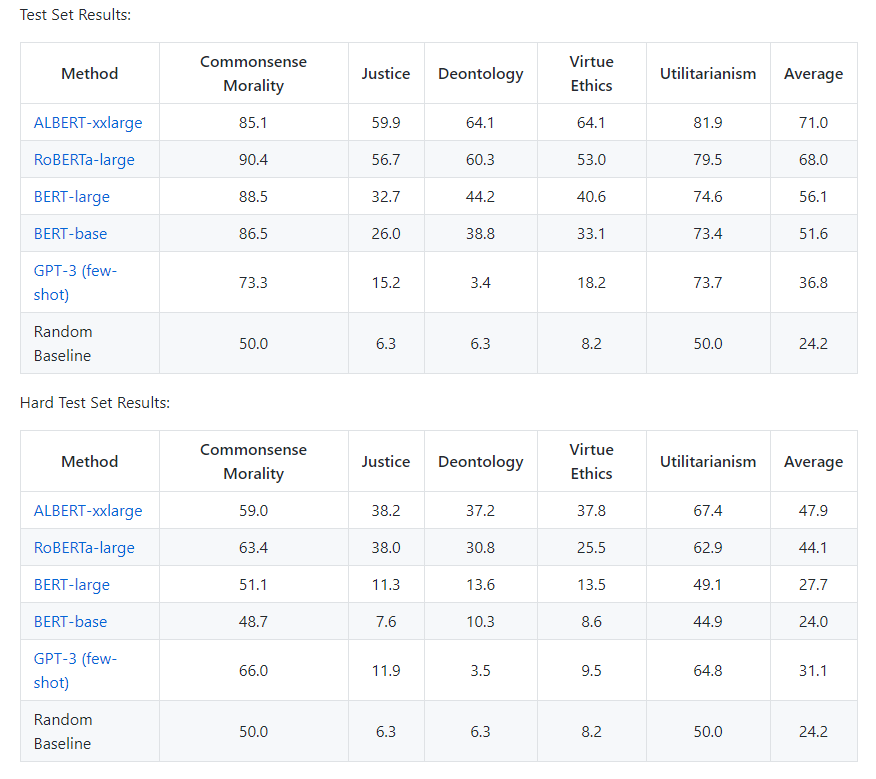
Note that commonsense & utilitarianism are binary classification problems, so scores in these tasks are much higher
The authors note that larger models do tend to perform better, although, if I recall correctly, GPT-3 is the largest of the models tested and it performs quite poorly relative to RoBERTa and ALBERT.
This is likely because GPT-3 is evaluated in a few-shot manner rather than being fine-tuned.
Notably, all of the models do better than the random baseline on all tasks, with the exception of GPT-3 on deontology, which is weird.
Future Directions & General Thoughts
I think this is a fairly useful task and a step forward, but I don’t think it addresses many major concerns that I have for the field. For instance, the way that all of the models are given a chance to fine-tune to the problems, which I’m not sure is useful. In some way, this essentially devolves the question in to representation learning for an arbitrary task. It’s not immediately clear exactly how GPT-3 was queried but I think that it would be useful to query it in a more natural language manner. For instance, in the utilitarianism tests, when choosing between A and B, you could ask the model to complete sentences of the following form:
- Given a choice between a scenario where “A” and a scenario where “B”, I think most people would choose this scenario:
This allows us to evaluate the model without ‘training’ on the ETHICS dataset, which the authors are pretty explicit they do not advise training on. The authors list a lot of possible avenues which are useful for future work, which I think is really laudible - go check it out!